最近做的react项目的总结、分享
前置知识
点我看详细
架构图示
点我看详细
提炼的几个点
1、同构思路汇总:
把拉取数据的逻辑写到 React Class 的 static 方法上,一方面服务端上可以通过直接操作 static 方法来提前拉取数据再根据数据生成 HTML,另一方面客户端可以在 componentDidMount 时去调用该静态方法拉取数据。
在做服务端渲染的时候遍历需要渲染的 components 去 同步 调用静态方法得到数据并吐出在页面上作为redux 的 initialState。在前端的 componentDidMount 方法中去判断是否在前端做 fetch。由于componentWillMount会在服务端渲染过程中执行,并且执行时this.props中的内容已经根据路由信息被修改,我们可以将ajax请求放入其中。我们可以在其中执行任意个ajax请求,由于store是可改变的,所以在请求结束后、reducer生效后我们便可以取到完整的、初始化过的store。
但仍然有一点需要注意——ajax请求时异步的,一次服务端渲染结束后,并不代表ajax请求就结束了,我们仍然需要一些方法来确定所哟请求确实结束,这里就需要一点设计了——我们可以在store中创建一个state专门用于表示初始化是否结束,并配以相应的action和reducer来修改它。
setImmediate不断检查store.getState().state.initDone来确定所有请求是否结束。
想要让服务端渲染出初始化store后的完整页面,方法很简单,只需要把第一次渲染后的finalState作为初始状态进行二次渲染即可。首先async库node环境和浏览器环境都可以使用。async.parallel 并行是关于并行启动I / O任务,而不是并行执行代码。 如果您的任务不使用任何定时器或执行任何I / O,则它们将实际上被串行执行。
刷新页面时存储请求路径,node通过async库执行并行等操作集中处理需要直出的数据请求,等获取到完整数据后,server结合页面模版生成html string, 连同store数据返回给前端。切换路由时如果不是之前刷新页面存储的跟路径则浏览器通过async发起异步数据请求并进行后续处理。
概念扩展:
关于平台区分:
同构一般只是在组件和逻辑编写上共用(包括组件、 Reducer Action / Reducer 等等业务和数据的处理逻辑),这覆盖到了绝大部分的日常业务代码。但根据平台不同最后基础层面还是会有部分区别。比如一个拉取数据的请求,在前端最后可能是 AJAX ,后端就是 http.request,(如果没有直接使用 isomorphic-fetch 这样的库的话)。
如果业务逻辑中还有少量要区分平台的代码,可以用 Webpack define plugin 来实现:设置一个环境变量来标识环境,编写分支。变量在编译时会替换为指定的值
页面渲染演变:
后台包办(jsp\php处理数据及页面,前端在后台项目中开发html、js、css等。问题是有时候简单的修改需要启动整个项目,服务庞大时会比较耗时,前后端糅合的地带变得越来越难以维护)
前后端部分分离(html、 js、css前端单独开发,开发完之后js、css、img等静态资源发布到cdn服务器上,html发布到后台——供后台模版编译)
前后端完全分离(html、css、img等静态资源放在cdn服务器上,访问页面时会先经由node服务处理页面数据,原本需要后台模版生成的页面可以通过node生成后返回浏览器)
使用React实现服务器渲染主要有以下好处:
1.利于SEO:React服务器渲染的方案使你的页面在一开始就有一个HTML DOM结构,方便Google等搜索引擎的爬虫能爬到网页的内容。
2.提高首屏渲染的速度:服务器直接返回一个填满数据的HTML,而不是在请求了HTML后还需要异步请求首屏数据。
2、涉及到的关键API
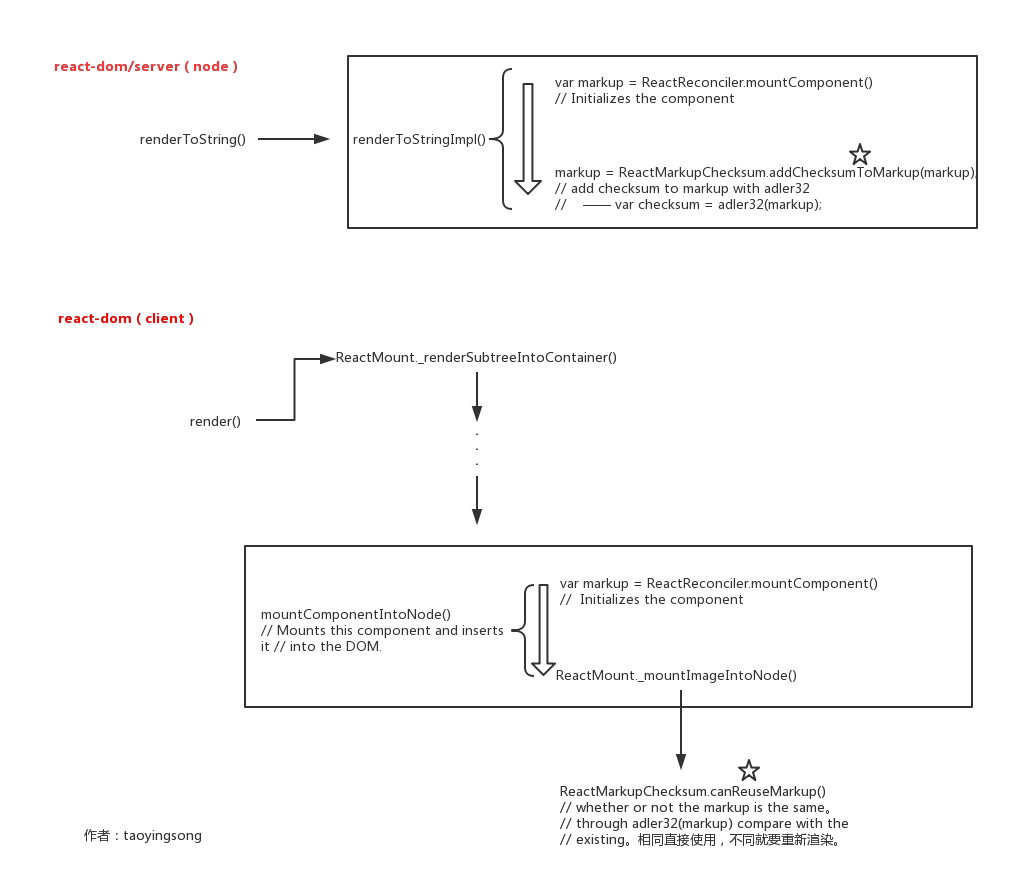
react-dom/server(server)
- renderToString:将React Component转化为HTML字符串,生成的HTML的DOM会带有额外属性:
- 各个DOM会有data-react-id属性,被React 用于区分DOM节点,当props或state发生变化时,React 可以根据此特性快速的更新DOM。
- 第一个DOM会有data-checksum属性。这个属性是通过adler32算法算出来:如果两个组件有相同的props和DOM结构时,adler32算法(有点类似于哈希算法)算出的checksum值会一样。
renderToStaticMarkup:
同样是将React Component转化为HTML字符串,但是生成HTML的DOM不会有额外属性,从而节省HTML字符串的大小。
当且仅当你不打算在客户端渲染这个React Component时,才应该选择使用ReactDOMServer.renderToStaticMarkup函数。下面有一些示例:
生成HTML电子邮件
通过HTML到PDF的转化来生成PDF
组件测试
等一些需要『纯』DOM的情况下
react-dom(client)
render ——我们常见的用于浏览器渲染render方法:
首先计算出组件的checksum值,然后检索HTML DOM看看是否存在数值相同的data-react-checksum属性,如果存在,则组件只会渲染一次。
也就是说,当服务器端和客户端渲染具有相同的props和相同DOM结构的组件时,该React组件只会渲染一次,否则舍弃服务端渲染结果重绘。
关于dom属性data-react-checksum源码解析:
(百科解释:checksum含义)

3、问题:server直出的页面如何获取client编译生成的带hash的资源文件,以更新html中对这些文件的引用?
项目中使用插件assets-webpack-plugin,将client的生成资源的映射表输出到assets.json并放到server中,供server产出首屏使用。
扩展:
web开发中静态文件版本控制的方法有两种:
- 通过静态文件的querystring中的版本号来表示不同版本的文件,
如<script type="text/javascript" src="a.js?v=1.1.0"></script>; - 通过在文件命中添加hash表示不同版本的文件,如
<script type="text/javascript" src="a_fdsf234d.js"></script>,
或者类似的,通过不同的文件路径区分:<script type="text/javascript" src="/js/a/fdsf234d/a.js"></script>
4、ReactElement vs ReactComponent:
When talking about the virtual DOM, it’s important to see the difference between these two.
- 元素(Element)是React的一个核心概念。一般情况下,我们用React.createElement|JSX来创建元素,但不要以对象来手写元素,只要知道元素本质上是对象即可。
- JSX本身是对JavaScript语法的一个扩展,看起来像是某种模板语言,但其实不是。但正因为形似HTML,描述UI就更直观了,也极大地方便了开发;当我们有一个JSX片段,它实际上是调用React API构建了一个Elements Tree(React.createElement最终返回了一个对象就是一个Elements Tree):借助babel-plugin-transform-react-jsx,上面的JSX将被转译成:
1
2
3
4var profile = <div>
<img src="avatar.png" className="profile" />
<h3>{[user.firstName, user.lastName].join(' ')}</h3>
</div>;1
2
3
4var profile = React.createElement("div", null,
React.createElement("img", { src: "avatar.png", className: "profile" }),
React.createElement("h3", null, [user.firstName, user.lastName].join(" "))
); - 一个元素(element)就是一个纯对象,描述了一个组件实例或DOM node,以及它需要的属性。它仅仅包含这些信息:组件类型,属性(properties),及子元素。
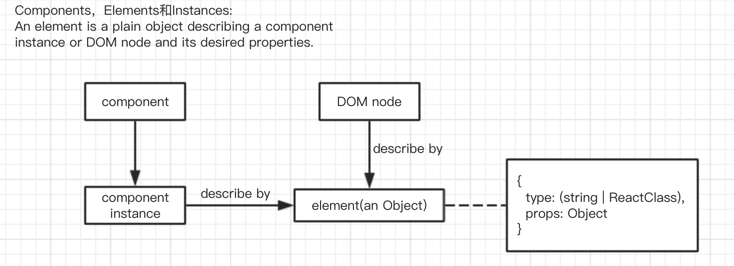
- react的render方法是一个由Elements Tree生成的函数,react的核心就是围绕Elements Tree做文章。
Elements Tree结合数据生成Virtual DOM Tree ,react更新此树以响应各种操作引起的data model变化。
参考:
https://reactjs.org/blog/2015/12/18/react-components-elements-and-instances.html
https://github.com/creeperyang/blog/issues/30(写的相当好)
5、虚拟dom&真实dom对比
论述1:
Let’s See Some Numbers!
根据网上一些数据可以看出:
加载页面后,jQuery显示最简单的“Hello,world”应用程序的总时间比纯JavaScript慢50ms,两者比React快大约3倍。Rendering时间react也是最慢的。
常识是:使用库比不使用库慢(加载库需要时间)。在实际操作DOM之前在内存中创建virtual DOM比仅仅直接操作DOM时要慢(创建virtual DOM需要时间)。
“Hello,world!”示例对React不公平,因为它们只处理页面的初始渲染。 React旨在管理对页面的更新。
但是,每次执行操作时,比较两个完整的虚拟DOM是低效的。对于复杂的用户界面,CPU要求可能很高。这个可以用过shouldComponentUpdate优化。
事实是,可能没法办确切证明使用虚拟DOM比直接更新DOM的方法更快,因为它取决于很多不同的因素,不过大多还是取决于你如何优化你的应用程序。如果你更新元素并不频繁,那么Virtual DOM并不一定适用,性能很可能还不如直接操控DOM。
react真正带给我们的是性能和生产力的益处。虽不一定就是最效率的,但大部分场景下这种方式更加效率。
论述2:
DOM操作(增删)本身不慢。缓慢的是浏览器在DOM发生变化时必须做的布局。每次DOM更改时,浏览器都需要重新计算CSS,进行布局并重新绘制网页。这是需要时间的。
以前直接使用 DOM API 比较繁琐,然后有了 jQuery 等库来简化 DOM 操作;但这没有解决大量 DOM 操作的性能问题。大型页面/单页应用里动态创建/销毁 DOM 很频繁(尤其现在前端渲染的普遍),我们当然可以用各种 trick 来优化性能,但这太痛苦了。而 Virtual DOM 就是解决问题的一种探索。
Virtual DOM 建立在 DOM 之上,是基于 DOM 的一层抽象,实际可理解为用更轻量的纯 JavaScript 对象(树)描述 DOM(树)。
操作 JavaScript 对象当然比操作 DOM 快,因为不用更新屏幕。我们可以随意改变 Virtual DOM ,然后找出改变再更新到 DOM 上。
论述3:
我们越来越多地推向动态Web应用程序(单页应用程序–SPA),DOM树越来越庞大。而我们又需要不断修改DOM树,这是一个真正的性能和发展的痛点。
典型的类似jQuery的事件处理程序如下所示:
- 遍历找到事件相关的节点
- 需要的话进行更新
这里有2个问题:
- 这很难管理。想象一下,你必须手动获取元素然后调用一个事件处理程序。如果你失去了上下文(发生异常),你必须深入了解代码才能知道发生了什么。既耗时又错误风险。当你在 JSX 中输入错误时,React 将不会编译,并打印输出错误的行号。
- 效率不高。我们是否需要手动更新全部节点?也许我们可以更聪明的更新节点。
问题1 在react中可以用声明(属性)式的方法解决,而不用自己在代码中作dom查询等相关处理。
问题2 是用Virtual DOM 它允许React在抽象世界中执行其计算,Virtual DOM可以diff,只更新需要更新的节点,可以减少不必要的屏幕渲染带来的性能消耗。
ps.
document is an abstraction of the root node
参考:
https://github.com/creeperyang/blog/issues/33
http://reactkungfu.com/2015/10/the-difference-between-virtual-dom-and-dom/
https://www.accelebrate.com/blog/the-real-benefits-of-the-virtual-dom-in-react-js/(精辟,后三节重点看)
https://stackoverflow.com/questions/21109361/why-is-reacts-concept-of-virtual-dom-said-to-be-more-performant-than-dirty-mode
6、单向数据绑定【|| 单向数据流】& 双向数据绑定【|| 双向数据流】
Part1
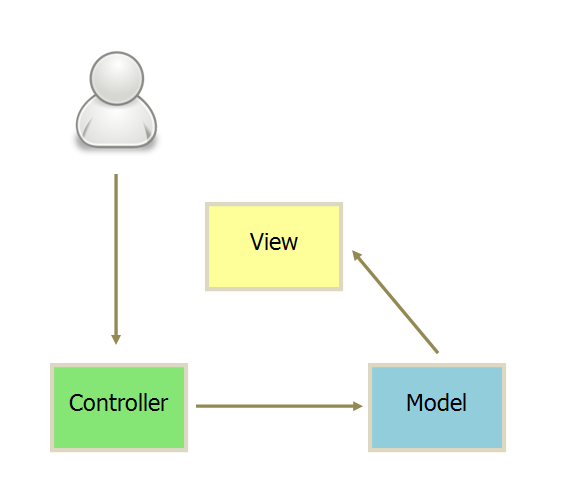
MVC
互动模式:
一种是通过 View 接受指令,传递给 Controller。
另一种是直接通过controller接受指令。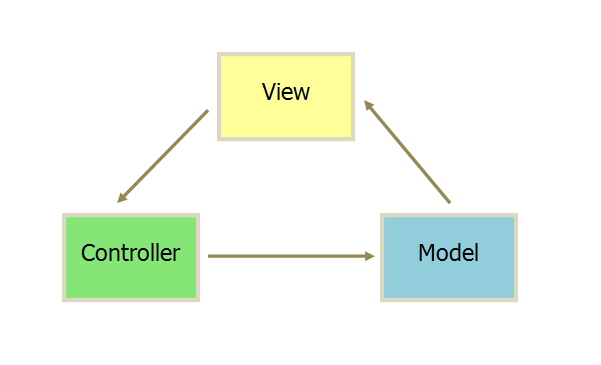
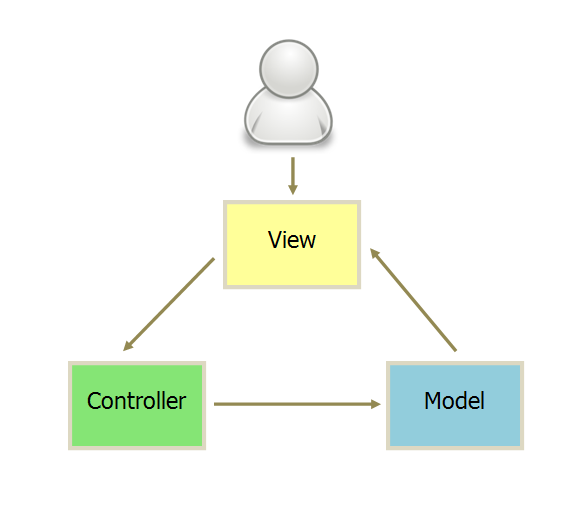
MVVM
互动模式同上
它采用双向绑定(data-binding):View的变动,自动反映在 ViewModel,反之亦然。(view model 是什么?看下边解释)
Vue实例就是ViewModel的代理对象
data: 指定了Model
View就是template
Vue作为MVVM框架会自动监听Model的任何变化,在Model数据变化时,更新View的显示。这种Model到View的绑定就是单向绑定。
View发生变化后会通过ViewModel改变Model进而再改变View这就是双向数据绑定。
(https://blog.csdn.net/hp910315/article/details/79658610)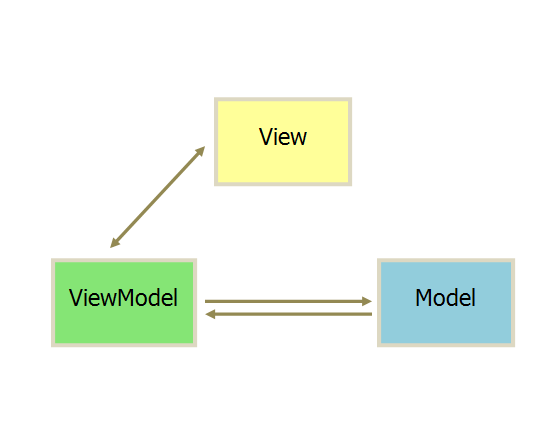
(参看:http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html)
Part2
v-model主要用在表单的input输入框,完成视图和数据的双向绑定,但是 Vue 是单项数据流,v-model 只是语法糖而已:
1 | <input v-model="something" /> |
第一行的代码其实只是第二行的语法糖。然后第二行代码还能简写成这样:
1 | <input :value="something" @input="something = $event.target.value" /> |
v-model只能用在<input>、<select>、<textarea>这些表单元素上(vuex中的数据好像也不能这样用v-model?),其他表单元素相使用类似v-model的功能可以自行模拟(参考https://github.com/wengjq/Blog/issues/17)。
关于v-model改变与vuex相关的state的论述(https://github.com/vuejs/vuex/blob/master/docs/zh-cn/forms.md 精彩)
总结来就vuex的state必须通过mutation handler改变,所有不能直接用v-model(会报错)需要自己重新封装语法糖在input事件中触发action,或者用defineproperty包装参数,在set中触发action。
Part3
双向绑定 = 单向绑定 + UI事件监听(事件获取数据作处理)。
对于非UI控件来说,不存在双向,只有单向。只有UI控件才有双向的问题。 比如父组件往子组件传送数据,vue、react是单向流动。
react不会直接更改该组件的state。它会通过setState更新data model,进而导致UI被更新。
如果你对React熟悉,你就会知道应用中的状态是(React)关键的概念。也有一些配套框架被设计为管理一个大的state对象,如Redux。此外,state对象在React应用中是不可变的,意味着它不能被直接改变(这也许不一定正确)。在React中你需要使用setState()方法去更新状态。
而在Vue中,则不需要使用如setState()之类的方法去改变它的状态,在Vue对象中,data参数就是应用中数据的保存者。
Part4
优缺点:
单向绑定的优点是相应的可以带来单向数据流,这样做的好处是所有状态变化都可以被记录、跟踪,状态变化通过手动调用通知,源头易追溯,没有“暗箱操作”。同时组件数据只有唯一的入口和出口,使得程序更直观更容易理解,有利于应用的可维护性。缺点则是代码量会相应的上升,数据的流转过程变长,从而出现很多类似的样板代码。同时由于对应用状态独立管理的严格要求(单一的全局store),在处理局部状态较多的场景时(如用户输入交互较多的“富表单型”应用),会显得啰嗦及繁琐。
基本上双向绑定的优缺点就是单向绑定的镜像了。优点是在表单交互较多的场景下,会简化大量业务无关的代码。缺点就是由于都是“暗箱操作”,我们无法追踪局部状态的变化(虽然大部分情况下我们并不关心),潜在的行为太多也增加了出错时 debug 的难度。同时由于组件数据变化来源入口变得可能不止一个,新手玩家很容易将数据流转方向弄得紊乱,如果再缺乏一些“管制”手段,最后就很容易因为一处错误操作造成应用雪崩。
最后总结我们要通过自己的业务场景合理的选择
(
https://www.cnblogs.com/Breaveleon/p/6680175.html
https://www.jianshu.com/p/4ec74cb5b748
)
7、CSS Modules的概念:
为了让 CSS 也能适用软件工程方法,程序员想了各种办法,让它变得像一门编程语言。从最早的Less、SASS,到后来的 PostCSS,再到最近的 CSS in JS,都是为了解决这个问题。
这里推荐 CSS Modules,它不是将 CSS 改造成编程语言,而是功能很单纯,只加入了局部作用域和模块依赖,这恰恰是网页组件最急需的功能。
局部作用域:
CSS的规则都是全局的,任何一个组件的样式规则,都对整个页面有效。
产生局部作用域的唯一方法,就是使用一个独一无二的class的名字,不会与其他选择器重名。这就是 CSS Modules 的做法。
CSS Modules 允许使用:global(.className)的语法,声明一个全局规则。凡是这样声明的class,都不会被编译成哈希字符串。
1 | .className { |
模块依赖:
在 CSS Modules 中,一个选择器可以继承另一个选择器的规则,这称为”组合”
局部作用域、js css可以共享变量、扩展性健壮性等为CSS的模块化考量的标准,这些问题CSS Modules思想可以得到相对完美的解决
选择器也可以继承其他CSS文件里面的规则。
1 | // another.css |
CSS工程化方案:CSS 预处理器:
- 内容:比如 Less 和 Sass,包括 PostCSS等
- 问题:
- JS CSS之间依然没有打通变量和选择器等
- 复杂的命名
CSS in JS: (如react-style)
- 概念:React 对 CSS 封装非常简单,就是沿用了 DOM 的 style 属性对象,这导致了一系列的第三方库,用来加强 React 的 CSS 操作。它们统称为 CSS in JS,意思就是使用 JS 语言写 CSS,里边会将一些常用的 CSS 属性封装成函数。
- 问题
- 无法使用伪类,媒体查询等
- 样式代码也会出现大量重复。
- 不能利用成熟的 CSS 预处理器(或后处理器 — css的压缩,前缀添加等)
CSS Modules: 使用JS 来管理样式模块,使其具备模块化的能力。(如使用webpack的css-loader、isomorphic-style-loader开启 )
- 所有样式都是局部作用域 的,解决了全局污染问题
- class 名生成规则配置灵活,可以此来压缩 class 名
- 只需引用组件的 JS 就能搞定组件所有的 JS 和 CSS
- 依然是 CSS,几乎 0 学习成本
参考:
http://www.ruanyifeng.com/blog/2016/06/css_modules.html
http://www.alloyteam.com/2017/03/getting-started-with-css-modules-and-react-in-practice/
https://github.com/kriasoft/isomorphic-style-loader/issues/15(里边有论述css不用抽离放在js中是可以的)
8、Babel
Babel 是一个 JavaScript 编译器——可以将ES6等代码转为ES5代码,从而在现有环境执行。
.babelrc:
1 | { |
babel-cli:
用于命令行转码, e.g.: $ babel example.js
babel-node: ——package.json中会用
babel-cli工具自带一个babel-node命令,提供一个支持ES6的REPL环境。随babel-cli一起安装。然后,执行babel-node就进入PEPL环境。在环境中babel-node命令可以直接运行ES6脚本。eg. $ babel-node es6.js
babel-register:——require的文件会先用babel转码
babel-register模块改写require命令,为它加上一个钩子。此后,每当使用require加载.js、.jsx、.es和.es6后缀名的文件,就会先用Babel进行转码。
babel-core:
如果某些代码需要调用Babel的API进行转码,就要使用babel-core模块。
babel-polyfill: 【补丁转义器】——转最新API
Babel默认只转换新的JavaScript句法(syntax),而不转换新的API,比如Iterator、Generator、Set、Maps、Proxy、Reflect、Symbol、Promise等全局对象,以及一些定义在全局对象上的方法(比如Object.assign)都不会转码。如果想让这个方法运行,必须使用babel-polyfill,为当前环境提供一个垫片。
transform-runtime(plugin): 【补丁转义器】——转core不能解决的es6
为了解决这种全局对象或者全局对象方法编译不足的情况,才出现了transform-runtime这个插件,但是它只会对es6的语法进行转换,而不会对新api进行转换。如果需要转换新api,也可以通过使用babel-polyfill来规避兼容性问题。
…
参考:
http://www.ruanyifeng.com/blog/2016/01/babel.html
https://juejin.im/post/5a79adeef265da4e93116430
9: Hash、Chunkhash、Contenthash、Slicing Hashes等:
hash:
- compilation在项目中【任何一个文件改动】后【就会被重新创建】,然后webpack计算新的compilation的hash值,这个hash值便是这里说的hash。
- 缺点:没发缓存资源
chunkhash:
- webpack的理念是把所有类型的文件都以js为汇聚点,不支持js文件以外的文件为编译入口。所以如果我们要编译style文件,唯一的办法是在js文件中引入style文件(import ‘style/style.scss’;)
- webpack计算chunkhash时,以main.js文件为编译入口,整个chunk的内容会将main.scss的内容也计算在内。
- webpack默认将js/style文件统统编译到一个js文件中,可以借助extract-text-webpack-plugin将style文件【单独编译输出】。从这点可以看出,webpack将style文件视为js的一部分。结果是js和css文件的hash指纹完全相同。不论是单独修改了js代码还是style代码,编译输出的js/css文件都会打上全新的相同的hash指纹。
contenthash :
- extract-text-webpack-plugin提供了另外一种hash值:contenthash。顾名思义,contenthash代表的是文本文件内容的hash值,也就是只有style文件的hash值。
修改配置为:new ExtractTextPlugin(‘[name].[contenthash].css’); - 遗憾的是修改css仍然会引起这个chunk的js的chunkhash发生变化,据说已经有优化,文档上没查到,可能需要看源码。
Slicing Hashes:
- [hash:8]指定保留几位hash值
参考:
https://www.cnblogs.com/ihardcoder/p/5623411.html
https://medium.com/@sahilkkrazy/hash-vs-chunkhash-vs-contenthash-e94d38a32208
10、路由
常用的 history 有三种形式:
browserHistory
hashHistory
createMemoryHistory
- React Router 是建立在 history 之上的。 简而言之,一个 history 知道如何去监听浏览器地址栏的变化, 并解析这个 URL 转化为 location 对象, 然后 router 使用它匹配到路由,最后正确地渲染对应的组件。
- 对IE8, IE9 支持情况,如果我们能使用浏览器自带的 window.history API,那么我们的特性就可以被浏览器所检测到。如果不能,那么任何调用跳转的应用就会导致 全页面刷新,它允许在构建应用和更新浏览器时会有一个更好的用户体验,但仍然支持的是旧版的。
- 当一个 history 通过应用程序的 push 或 replace 跳转时,它可以在新的 location 中存储 “location state” 而不显示在 URL 中,这就像是在一个 HTML 中 post 的表单数据。
- 项目中使用进行页面刷新跳转,使用组件进行页面不刷新的路由跳转。首次请求会经过server, 后边路由变化被client监听。
- hash 部分并不会被浏览器发送到服务端,也就是说不管是请求 http://domain.com/index.html#foo 还是 http://domain.com/index.html#bar ,服务只知道请求了 index.html 并不知道 hash 部分的细节。而 History API 需要服务端支持,这样服务端能获取请求细节。
11、GraphQL是什么?
GraphQL 即 图表化查询语言
它定义了一套类型系统(Type System),你可以把GraphQL的查询语言(Queries)当成是没有值只有属性的对象,返回的结果就是有对应值的对象,也就是标准的JSON。有点后台的model层的感觉。多个资源一次请求(不需要分别请求,相当于一个代理)
那么我如何上手 GraphQL?
通常来说,一个 GraphQL 驱动的 app 起码需要以下两个组件:
一个 GraphQL 服务端 来为你的 API 提供服务。
一个 GraphQL 客户端 来连接你的节点。
12、 Externals: 外部扩展
externals 配置选项提供了「从输出的 bundle 中排除依赖」的方法。相反,所创建的 bundle 依赖于那些存在于用户环境(consumer’s environment)中的依赖。
环境中的依赖可以通过script 标签require等方式引入。