数据流方案选用及相关代码组织方式对前端项目影响非常大,本文整理了tkestack项目前端数据流方案及项目架构的优化改进过程,最终结合项目以近乎颠覆的方式输出了一个能解决我们遇到大量问题的方案。希望给读者能带来些许思考、启示或帮助。
提纲:
一、 初始数据流方案的基本情况 及 开发过程中发现的问题(ff-redux)
- 基本情况(4)
- 问题(5)
- 造成的结果
二、 思考、尝试、分析总结(useReducer、useContext)
- 思考(2)
- 尝试
- 分析总结(3)
- 结论
三、 比对、思考、选择(关于dva、umi、redux-toolkit)
- 方案比对(3)
- 思考(2)
- 选择
四、 规则制定、应用
- 规则制定
- 背景
- 规则一
- 规则二
- 规则三
- 应用
五、 优化改进(4)
六、最终
一、 初始数据流方案的基本情况 及 开发过程中发现的问题
基本情况
- 项目初始数据流方案是原始团队基于redux + redux-thunk的封装
- 封装分为3部分:ff-redux、ff-component、ff-validator
- ff-redux: 对外暴露了至少82个方法,和redux相关的至少34个方法,找到的文档中介绍了18个方法;对外至少暴露了56个TS类型定义,找到的文档中介绍了15个左右。
- ff-component: 对外暴露了2个方法,22个封装组件(主要为基于tea、ff-redux高度定制化的表单元素组件、table组件等。表单元素值、校验结果等相关数据全部通过redux管理)
- ff-validator: 对外暴露了7个方法
- 基于角色将action和reducer文件分别组织在相关文件夹中
- 复杂项目:十几个模块;几十个页面;上百个组件;多版本,多环境;接口众多且数据复杂,k8s大对象,上百条不重复字段的处理,各种不同类型的数据,数据深度5、6层情况常见
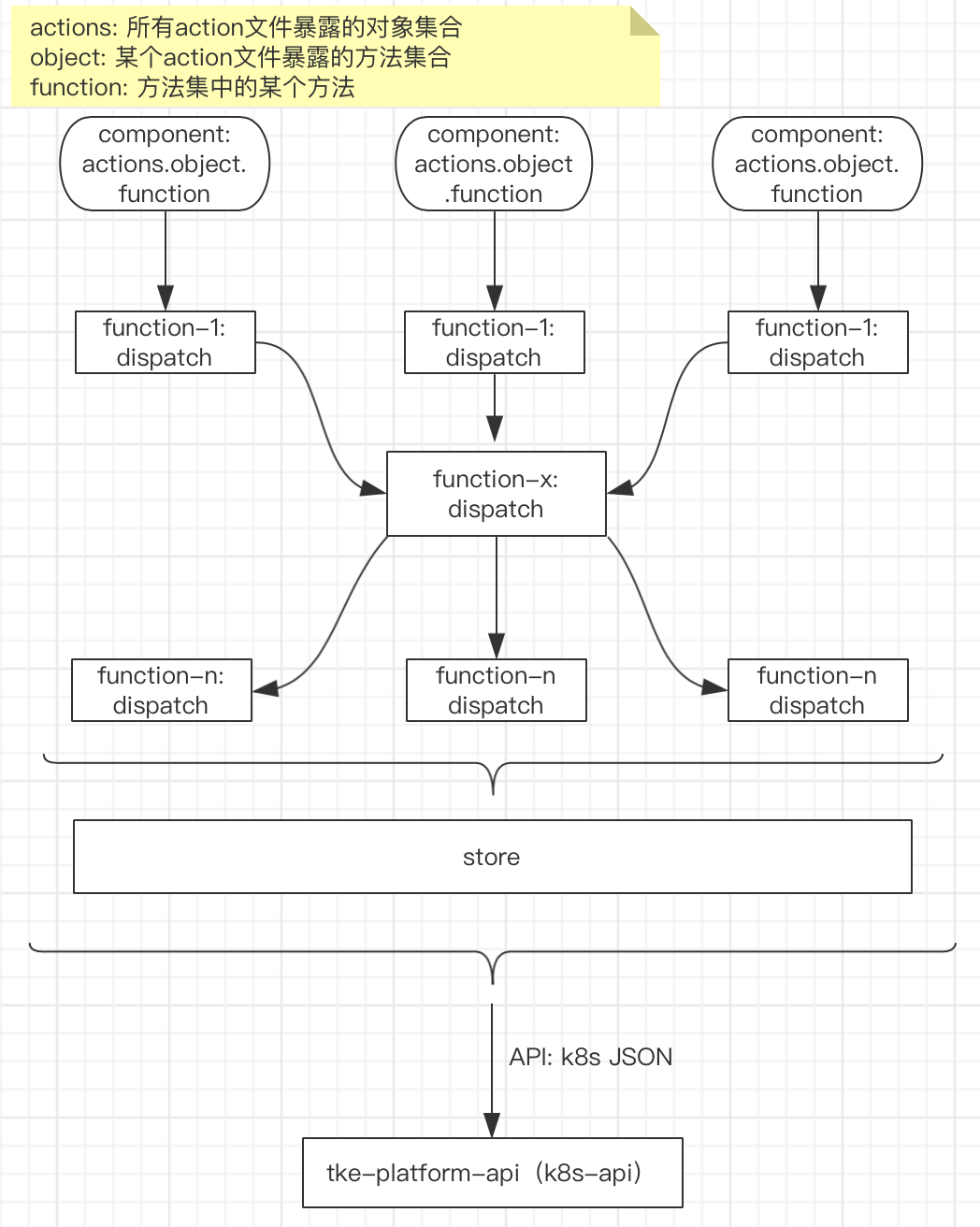
1). dispatch链 层级较深时追到过6层左右
2). dispatch链 涉及到多个action文件
3). action文件的function中可能涉及1到多个dispatch的调用逻辑、router逻辑、数据处理逻辑等
4). 大部分function中都会有变更store值的dispatch
问题
- 项目相关的所有数据基本都通过redux管理(包括校验等组件临时数据),组件没有明确的接口定义,通讯几乎全靠store,使用数据的时候几乎都是直接this.props获取,黑盒太多
- 数据流方案过度封装,增加了学习成本。dispatch链路很长(追到过6层的),中间dispatch的方法可能被多个链路使用;个别封装导致技术滥用,比如ff-redux封装方法中的finish钩子,里边会处理相关api调用获取到数据后的公共逻辑,这些时常导致在某个action方法调用之后产生意想不到的影响,也使数据变更难以追踪。
- 部分文件夹(actions、components等)下同级文件数量达到三四十个之多,很多文件名也比较雷同,难以查阅。
- 后台缺少控制层能力,使得接口能力不够灵活,一定程度上导致了前端action部分逻辑的臃肿、混乱 。比如:复合数据的处理都需要在前端进行;前端必须适配接口的固定调用模式,相关数据处理逻辑(即便是不用前端关心的数据)必须放在前台。
- ff-redux没有封装工具Redux DevTools,之前一直通过log插件的log追踪相关数据变更,调试起来非常痛苦。
造成的结果
数据流很难追踪,项目代码不可读、难以维护。
二、 思考、尝试、分析总结、结论(hooks)
思考
思考1:
React是用数据驱动视图的,和数据相关的数据流方案是成就一个优秀React项目的关键,我希望通过优化甚至颠覆当前项目的数据流方案的使用方式,从根本上解决上述开发过程中发现的一些问题。
思考2:
React16.8的Hooks新特性引入了useReducer 和 useContext,这为数据流方案的实现提供了新的可能,可能是一个突破口。
尝试
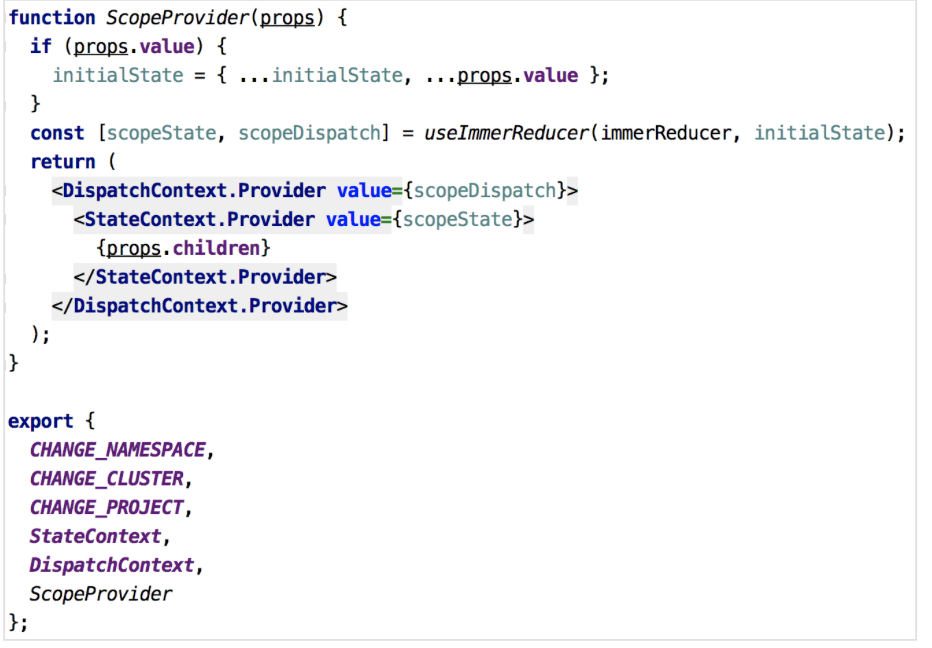
在新开发的模块中尝试通过内置Hooks的useReducer、useContext替代原来的数据流方案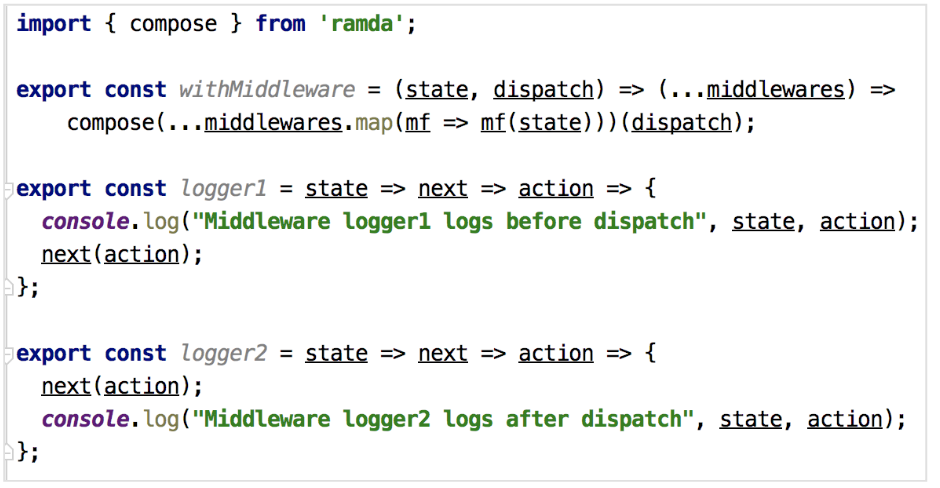
分析总结
- 使用useContext和useReducer可以复制Redux的功能,但是无法使用像Redux DevTool这样可以在开发时进行调试的重要工具、没有Redux封装提供的能力(比如combineReducers,createStore)、扩展性不足(需要自己手动书写、集成中间件)等,新特性本身并不会对数据流处理的编程思路产生实质的改变,是否真的有必要重新造轮子,这样做的主要优势在哪里,这里要打一个大大的问号。
- 使用React Hooks useContext的最佳情况是在小型应用程序中,或在组件之间共享小段信息,不推荐将其作为复杂项目的数据流方案。
- 开发人员倾向于认为useReducer可以代替状态管理库。但实际上,我觉得它的使用应限于组件。
结论
通过内置Hooks的useReducer、useContext替代原来的数据流方案并不是一个理想方案。问题没有解决,仍然需要想办法。
三、 比对、思考、选择(dva、umi、redux-toolkit)
方案比对
据我了解公司其他团队React项目数据流方案用的比较多的是dva。
dva 是一个基于 redux 和 redux-saga 的数据流方案。dva可以大量减少模板代码编写,避免文件( reducer, action, saga, component 等等)切换造成编程思路容易被打断的问题,减少频繁切换的时间消耗。dva可以让我们用更容易的方式创建saga。dva还额外内置了其他能力。umi是一个可扩展的企业级前端应用框架,数据流方案只是其一部分。
Redux Toolkit是redux官方后来出的一个包。
Redux Toolkit默认只有数据流的处理能力,提供了对redux 和 redux-thunk的封装。数据流处理能力在文件及代码组织上和dva相当,额外的使用redux toolkit后书写时不用过多关注action的type。
思考
无疑,dva的封装很好的简化了开发体验,能有效解决我们项目在数据流方案上遇到的问题,甚至能做更多。
但很关键一点是,我现在不是在作一个新项目,接入dva之后我在项目中能否增量替换现有数据流方案是个问题,官方文档看到的介绍是全量接入使用的,没有看到增量替换的相关介绍。强行可能出现未知问题。umi更不可能增量接入。dva的能力更加全面,Redux Toolkit的数据流方案单向能力上更加突出。
Redux Toolkit是对redux能力的升级,在我所做项目中引入之后可以对当前数据流方案进行增量改进。
选择
介于上边的比对思考,在项目不能直接重写的情况下我最终选择使用Redux Toolkit。
四、 规则制定、应用
规则制定
背景
- tkestack项目代码是从公有云的代码演变而来,和公有云的能力在迭代的过程中会互相补充,产出一样或相似度很高的功能模块。产品多次希望这些功能模块的代码有复用的可能,以尽可能的避免重复开发。
- 上边一中的问题
规则一:代码组织时基于功能进行分类,以更方便共享
代码的组织方式可以分为2种:
【基于角色的分类(role based)】
【基于功能的分类(feature based)】
a. 基于角色的分类
这种组织方式是我们项目,也是目前我看到的众多项目的组织方式。
把所有 reducer 放在一个目录,
把所有 action 放在一个目录,
把所有的 react 组件放在一个目录,
…
b. 基于功能的分类
一个目录代表的功能模块既包含react组件,又包含action、reducer文件等
因为基于功能的分类每个目录是一个功能的封装,所以会更方便共享
规则二:只对必要的数据使用redux管理
从组件角度看,以下场景可以使用Redux管理数据,否则考虑在组件内部管理自身状态
- 某个组件的状态,需要共享
- 某个状态需要在任何地方都可以拿到
- 一个组件需要改变全局状态
- 一个组件需要改变另一个组件的状态
规则三:组件接口调用时要体现出必要的参数信息,不要黑盒调用
应用
五、 优化改进
(1).
因为异步中间件redux-thunk 和 redux-promise 改变了 action 的含义,使得 action 变得不那么纯粹了,因此dva选用了优雅而强大的redux-saga。
同理,我也想在项目中使用redux-saga,同时我也希望saga能够更容易的创建,于是我基于redux-toolkit封装了一个包redux-toolkit-with-saga,这个包提供了2个能力:
a. 以类似dva的方式一样在redux-toolkit中结构化的组织开发saga。
1 | const testSliceSaga = createSliceWithSaga({ |
b. 以插件的方式接入,结构化的组织开发saga:
1 | const testSagaSlice = createSagaSlice({ // saga组织部分 |
具体选用什么方式组织代码,可以依据个人喜好。
(2).
集成工具Redux DevTools
(3).
和后台沟通,在后台增加控制层,确保接口复合数据的处理能力和使用的灵活性等
(4) .
状态规范化 & 管理规范化数据
规范化状态数据的基本概念:
- 每种类型的数据在状态中都有其自己的“表”。
- 每个“数据表”应将单个数据项存储在一个对象中,其中数据项的ID作为键,而数据项本身作为值。
- 对单个数据项的任何引用都应通过存储数据项的ID来完成。
- ID数组应用于指示顺序。
1 | const blogPosts = [ |
1 | { |
比对:
- 因为每个item仅在一个地方定义,所以如果该item被更新,我们不必尝试在多个地方进行更改。
- Reducer逻辑不必处理深层嵌套,因此它可能会更简单。
- 现在,检索或更新给定item的逻辑非常简单且一致。给定item的类型和ID,我们可以通过几个简单的步骤直接查找它,而无需深入研究其他对象来查找它。
- 由于每种数据类型都是分开的,因此像更改注释文本这样的更新仅需要树的“comments> byId> comment”部分的新副本。通常,这意味着UI的较少部分需要更新。相反,以原始嵌套形状更新comment将需要更新comment object,父post object,post objects数组,并且可能导致UI中的所有Post组件和Comment组件重新渲染。
事实证明,让已连接的父组件简单地将item ID传递给已连接的子组件是在React Redux应用程序中优化UI性能的一个很好的模式,因此保持状态规范化对于提高性能起着关键作用。
这部分优化强烈建议看下这2篇文档:
Normalizing State Shape
Updating Normalized Data
六、最终
重点:
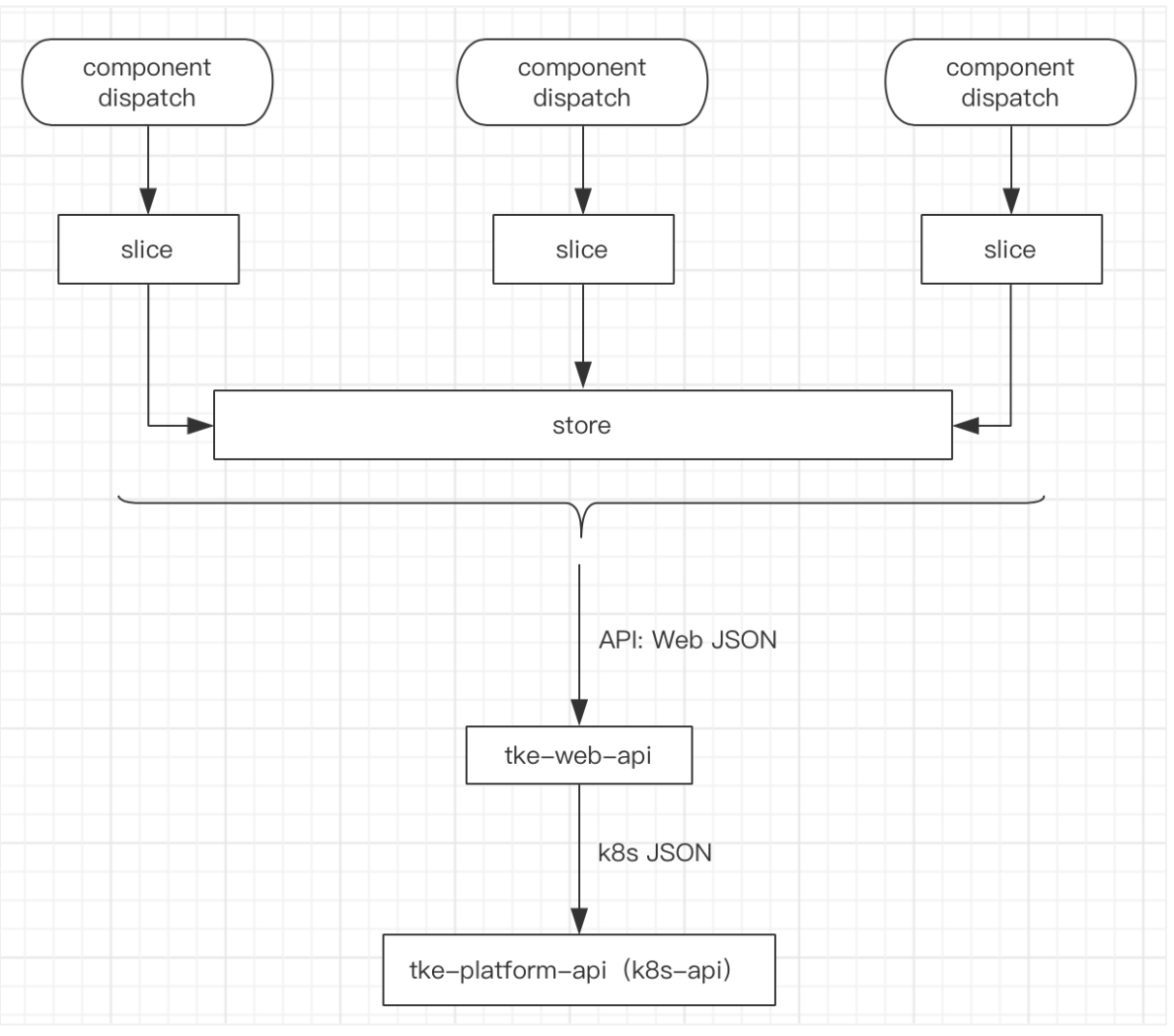
- 以上原始action方法层中庞杂的调用链逻辑前置到component中,避免action方法层中dispatch的方法之间的交织影响,使数据处理逻辑更可读可追踪。
- 现在dipatch的action和reducer逻辑整合在slice中,store中数据的处理作为这部分关注的重点。这里消除了之前大量的模板代码和文件频繁切换的影响,另外在dipatch调用链逻辑上移到component中及只在redux中管理必要的数据之后,slice这一层随之会变得非常清爽易读。
- 之前action方法层中的部分数据处理后制到tke-web-api层,使前端可以更聚焦前端应该关注的东西。
最终最初的问题都得到了解决。